영속 객체와 영속 컨텍스트
- 영속 엔티티(객체)
- DB 데이터에 매핑되는 메모리상의 객체
- @Entity 클래스로 생성한 객체
- 영속 컨텍스트
- 일종의 메모리 장소
- EntityManager 가 관리할 엔티티 객체 보관
- 엔티티 타입, 식별자 → Map 과 같은 형태로 저장
- 캐시
- Repeatable Read 효과
- 동일 식별자로 DB에서 조회한 데이터는 영속 컨텍스트에 저장
- 같은 데이터를 다시 한번 조회한다면, DB 조회가 아닌 캐시에 저장된 데이터를 불러옴
- 영속 객체 라이프사이클
- EntityManager 의 변경 추적 대상인 상태에서는 commit 시 DB에 변경 사항이 반영
- managed
- 영속 컨텍스트 내 보관되며, 변경사항 추적되는 상태
- persist() 나 find() 실행 시 해당 객체는 영속 컨텍스트 내 managed 상태
- removed
- 영속 컨텍스트에서 삭제된 상태(삭제되었다는 상태를 저장)
- detached
- 변경 추적 대상 x
- EntityManager가 close() 되었을 때
- detache() 를 통해 강제로 분리했을 때
- merge()를 통해 detached 상태인 객체를 다시 managed 로 변경 가능
- 대량 변경은 굳이 JPA 로 하기보단 직접 쿼리 실행이 나음
연관 매핑
- 엔티티가 다른 엔티티를 필드로 갖고있는 경우
- 설계 시 밸류로(Embeddable) 매핑해도 되는 경우를 잘 고려해 봐야 함
1-1 단방향 연관
- 참조키를 이용한 1-1 관계
- @OneToOne, @JoinColumn(name=”참조할 키”)
- @OneToOne 기본값이 FetchType.EAGER 방식. LAZY로 바꿀 수 있음
- 식별자 공유 방식 1-1 단방향
- @OneToOne, @PrimaryKeyJoinColumn(name = “참조할 키”)
N-1 단방향 연관
- 참조키를 이용한 N-1 관계
- @ManyToOne, @JoinColumn(name = “연결할 키”)
- 참조한 테이블이 left join 되어 조회됨
1-N 단방향 연관
- 콜렉션을 사용한 매핑
- Set
- @OneToMany, @JoinColumn(name = “참조하려는 주체 입장에서 참조대상 테이블과 연결할 필드명”)
- List
- List 의 인덱스를 보관할 컬럼이 N 측에 사용
- @OneToMany, @JoinColumn(name = “참조하려는 주체 입장에서 참조대상 테이블과 연결할 필드명”), @OrderColumn(name=”인덱스를 담을 컬럼명”)
- Map
- Map 의 Key 를 보관할 컬럼이 N 측에 사용
- @OneToMany, @JoinColumn(name = “참조하려는 주체 입장에서 참조대상 테이블과 연결할 필드명”), @MapKeyColumn(name=”Map의 키로 사용할 컬럼명”)
영속성 전파
- 연관된 엔티티에 영속 상태를 전파
- 저장할 때 연관된 엔티티도 함께 저장
- 연관애노테이션- cascade cascadeType 설정
- PERSIST : 해당 엔티티 저장 시 연관된 엔티티도 같이 저장
- 특별한 이유가 없다면 사용하지 않는 것을 권장
연관 고려사항
- 연관 대신에 ID 값 참조 고려
- 조회는 전용 쿼리나 구현 사용 고려(CQRS)
- 엔티티가 아닌 밸류인지 확인
- 1-1, 1-N 관계에서 특히
- 1-N 보다는 N-1 권장
- 양방향 사용하지 않는 것을 권장
CQRS
- 명령(상태변경) 모델과 조회 모델 분리
- JPA 로만 모든 일들 (조회 및 상태변경, 페이징, 상세보기 등..) 처리할 수는 있지만 무리가 있음
- 참조 : 최범균 - CQRS 아는 척하기
- CQRS 아는 척하기 1
JPQL
- JPA Query Language
- 테이블 대신 엔티티 이름, 속성 사용
- :매치할 파라미터
- 기본 구조
- TypedQuery<결과타입> 으로 쿼리 생성
- select 별칭 from 엔티티명 별칭(엔티티명 as 별칭)
- 생성 : createQuery(쿼리, 결과타입)
- 파라미터 지정 : setParameter(”파라미터명”, “파라미터값”)
- 페이징 처리
- setFirstResult(시작행)
- setMaxResults(최대 결과 개수)
- 복잡한 쿼리의 경우 일반 쿼리 사용 고려
- 다중 테이블 조인
- DBMS에 특화된 쿼리 필요할 경우
- 서브쿼리
- 통계, 대량 데이터 조회/처리
Criteria
- 코드로 쿼리를 구성하는 api
- 기본 사용법
- CriteriaBuilder 생성
- 1을 통해 CriteriaQuery 생성
- 제네릭, 파라미터로 쿼리 결과 타입 지정
- cq.from(접근할 root 엔티티 타입)
- cq.select(root)
- CB를 이용해 Predicate 생성 cq.where(cb.equal(root.get(”hotelId”), “H001”));
- cq.orderBy(cb.asc(root.get(”id”));
- 마지막으로 CQ를 이용하여 TypedQuery 생성
- 장점
- 타입에 안전한 코드 생성 가능
- 동적 검색조건 지정 가능
- 예) if ㅁㅁ이상일 경우 조건 추가
JPA 기타 특징
- AttributeConverter
- 매핑을 지원하지 않는 자바타입과 DB 타입 간 변환 처리
- AttributeConverter 구현 클래스 생성
- 적용하고자 하는 필드 위에 다음과 같이 지정
@Convert(converter=생성한 컨버터 타입)
- @Formula
- 조회에서만 매핑 처리(insert, update는 매핑 대상 아님)
- sql의 실행결과를 특정한 속성으로 매핑하고자 할때 사용
- @DynamicUpate, @DynamicInsert
- 수정쿼리는 기본적으로 모든 컬럼 포함
- 변경된 컬럼만 update 쿼리에 포함
- null이 아닌 컬럼만 insert 쿼리에 포함
- 클래스에 애노테이션 지정
- @Immutable
- 변경 추적 대상에서 제외 처리
- 변경 추적 위한 메모리 사용 감소
- 주로 조회 목적으로만 사용되는 엔티티 매핑에 사용
- @Subselect
- select 결과를 엔티티로 매핑
- 수정 대상이 아니므로 @Immutable과 함께 사용
- 클래스에 에노테이션 지정
- 기타
- 상속 매핑
- 네이티브 쿼리
- 하이버네이트 애노테이션
- @CreationTimestamp
- @UpdateTimestamp
Spring Data JPA
- 정해진 규칙에 따라 인터페이스만 작성하면 끝
- Spring Boot + Spring Data JPA 같이 사용할 시 다음과 같은 부분 자동설정
- persistence.xml
- EntityManagerFactory
- 스프링 트랜잭션 연동
- EntityManager 연동
- 사용방법
- 엔티티 단위로 Repository 상속한 타입 추가
- 스프링 데이터 JPA 가 제공하는 타입
- 이 인터페이스를 상속한 인터페이스를 이용해 빈 생성
- Repository<엔티티타입, 엔티티 식별자 타입>
- 규칙에 맞는 메서드 정의
- save()
- findById()
- delete()
- 엔티티 단위로 Repository 상속한 타입 추가
메서드 작성 규칙
- 식별자로 엔티티 조회
- findById
- T findById(ID id)
- 없으면 null
- Optional findById(ID id)
- 없으면 empty Optional
- T findById(ID id)
- findById
- 엔티티 삭제
- 삭제할 대상이 존재하지 않으면 예외
- void delete(T entity)
- void deleteById(ID id)
- 엔티티 저장
- void save(T entity)
- T save(T entity)
- save() 동작 방식
- 새 엔티티면 EntityManager#persist()
- 새 엔티티가 아니면 EntityManager#merge() 실행
- → 그 때문에 insert 쿼리 이전에 select 작업 발생
- 새 엔티티인지 판단하는 기준
- Persistable 을 구현한 엔티티
- @Version 속성있을경우
- 버전 값이 null일 경우
- 식별자가 참조 타입일 경우
- 식별자가 null 일 경우
- 식별자가 숫자 타입일 경우
- 식별자가 0일 경우
- 특정 조건으로 찾기
- findAll : 모두 조회
- findBy프로퍼티 : 프로퍼티가 특정 값인 대상
- 예) List findByGradeAndName(Grade g, String name)
- 조건 비교

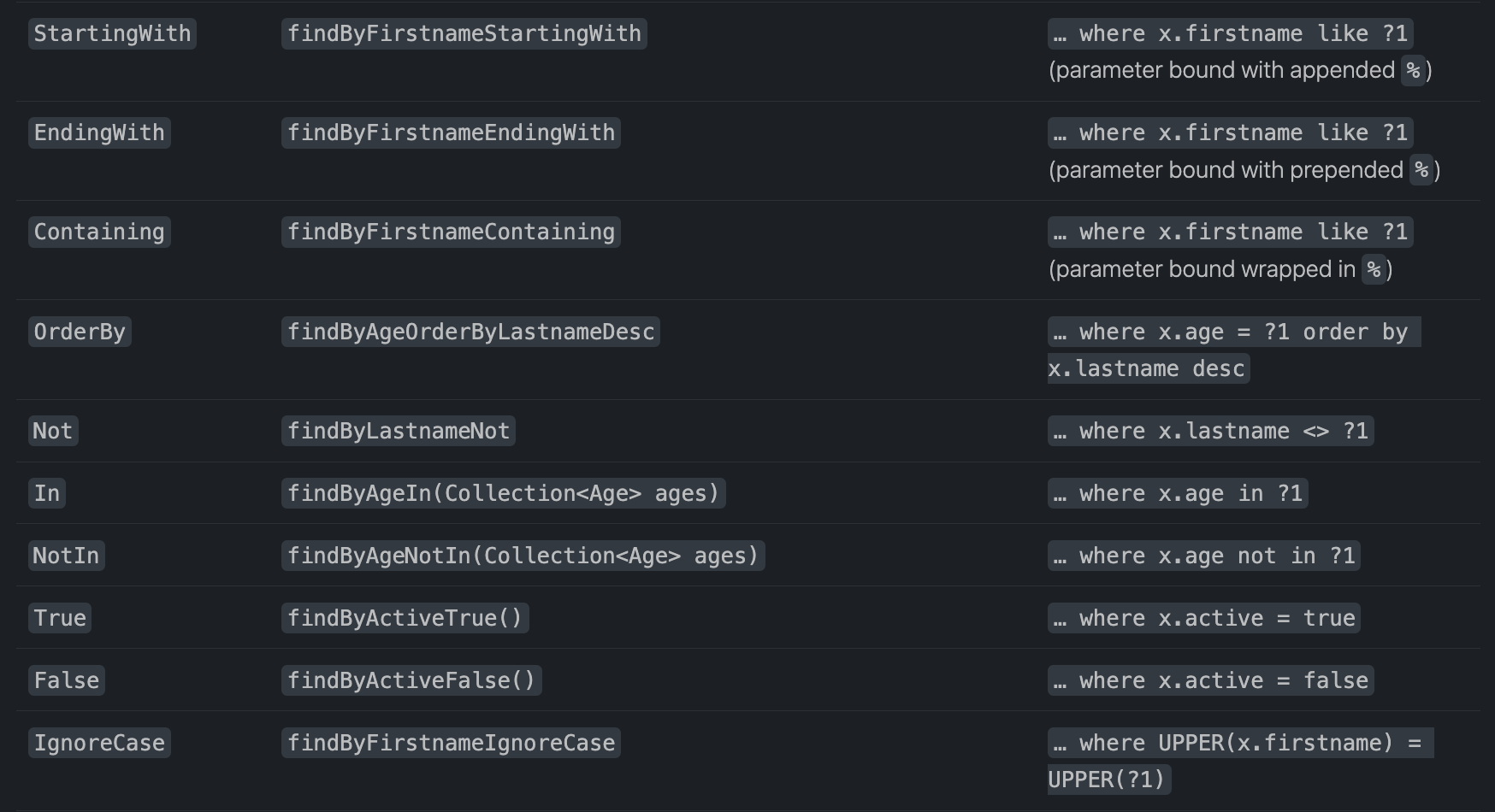
- 검색조건이 단순하지 않으면 @Query, SQL, 스펙/QueryDSL 사용 권장
정렬, 페이징, @Query
- 정렬
- find 메서드 뒤에 OrderBy 붙이기
- findByNameLikeOrderByNameDesc()
- 여러 프로퍼티 지정 가능
- Sort 타입 파라미터 사용
- find 메서드 뒤에 OrderBy 붙이기
- 페이징
- Pageable/PageRequest 사용
- ofSize : 한 페이지에 조회할 개수
- withPage : 조회할 페이지 번호. 0부터 시작
Pageable pageable = PageRequest.ofSize(10).withPage(1); - withSort 를 통해 Pageable에 정렬 설정 가능
- Pageable/PageRequest 사용
- 페이징 조회 결과 Page 타입으로 구하기
- Page 타입 : 페이징 처리에 필요한 값들 포함
- 전체 페이지 개수, 전체 개수…
- Pageable을 사용하는 메서드의 리턴 타입을 Page로 지정하면 됨
Page<User> findByEmailLike(String keyword, Pageable pageable);
- Page 타입 : 페이징 처리에 필요한 값들 포함
- @Query
- 메서드 명명 규칙이 아닌 JPQL 직접 사용
스펙
- Specification : 검색 조건을 생성하는 인터페이스
- Criteria 를 이용해서 검색 조건 생성
- 리포지토리에 findAll 메소드에 스펙을 전달하면 스펙을 통해 검색조건을 생성하여 조회
List<User> findAll(Specification<User> spec);- 구현
- Specification 인터페이스 구현
- toPredicate() 작성
- 람다로 간결하게 구현
public class UserSpecs {
public static Specification<User> nameLike(String value) {
return (root, query, cb) -> cb.like(root.get("name"), "%" + value + "%");
}
}사용
UserNameSpecification spec = UserSpecs.nameLike("이름");
List<User> users = userRepository.findAll(spec);- or/and 메서드를 이용해 조합
- 스펙 여러개 생성
- Aspec.and(Bspac) → findAll 메소드 전달
- 한번에 and 로 엮어서 전달
- 선택적 조합
- Specification.where(null) 로 빈 스펙 생성
- 조건에 따라 스펙 조합
- Spec + 페이징 + 정렬
- if 절을 덜 쓰기 위한 SpecBuilder 구현
- 람다식을 이용
Specification<User> specs = SpecBuilder.builder(User.class) .ifHasText(keyword, str -> UserSpecs.nameLike(str)) .ifNotNull(dt, value -> UserSpecs.createdAfter(value)) .toSpec();- 참조
- Spring Data Specification 단순 조합을 위한 간단한 SpecBuilder
기타
- cout 메서드
- 특정 조건을 지정하거나 스펙을 이용해 개수 세기
- @Query 애노테이션 내에 JPQL이 아닌 일반 SQL 실행 → 네이티브 쿼리
- @Query(value = “쿼리내용”, nativeQuery = true)
- 한 개 결과 조회
- List대신 타입, Optional<타입> 을 리턴 타입으로
- 조회 결과 개수가 두개 이상이면 예외 발생
- Repository 하위 인터페이스
- 하위 인터페이스를 상속하면 관련 메서드 모두 포함되어 추가해줄 필요 없음
- Repository 를 상속받고 딱 필요한 메서드만 만드는 방법 권장
인프런에서 '최범균'님의 'JPA & Spring Data JPA 기초' 라는 강의를 들으며 노션에 정리한 내용 입니다.
이전에 최범균님의 '도메인 주도 개발 시작하기'란 저서를 감명깊게(?) 본 경험이 있었는데
인프런 강의를 구경하다 우연히 발견하고 마침 JPA 복습도 필요했기에 바로 수강했습니다.
코드 예제와 함께 빠르게 JPA, Spring Data JPA 내용을 훑어볼 수 있어 좋았네요.
다른 좋은 강의로 같은 저자 분의 '객체 지향 프로그래밍 입문' 이란 강의도 있습니다.
이것도 정리를 해두었지만 캡쳐가 많아 블로그에 게시하지는 못하겠네요.
항상 예시를 들어가며 이해할 수 있도록 설명을 잘 해주시기 때문에 입문용, 혹은 복습용으로 추천드립니다!
댓글 피드백은 언제나 환영합니다!

'BackEnd' 카테고리의 다른 글
| Node.js 의 이벤트 루프 (1) | 2024.03.05 |
|---|---|
| JPA - 영속성 컨텍스트 (1) | 2024.01.15 |
| DDD - 엔티티와 밸류 (0) | 2024.01.12 |
| Spring VS SpringBoot (0) | 2020.07.23 |
